NLP: Gaining insights from text reviews

Fredrik Olsson
Data Scientist

Every time we express ourselves, either verbally or in written text, these expressions carry a lot of information. What subjects we talk about, if we express opinions or facts, our selection of words etc., all of which add some kind of information to our expressions, and can be interpreted and extracted to gain insights.
With all the web content in terms of e.g. consumer reviews and social media posts we have today, companies now have access to tons of useful information that can help improve their business. In most cases however, the huge amount of data available is not manageable to process manually, and we thus need a way to automate this process. This leads us in on the field of machine learning called Natural Language Processing, or NLP.
Natural Language Processing
NLP is what we call the large subfield of machine learning that deals with data in the form of natural language, both in terms of written text and speech. In other words, NLP is the subfield of machine learning that gives computers the ability to read, understand and derive meaning from the human languages. NLP is one of the most actively researched fields within machine learning at the moment, and great improvements have taken place alongside developments in deep neural networks in recent years.
Deep learning
In many machine learning problems we use tabular data, i.e. data that fit well into the traditional row and column structure. In these cases, classic machine learning models like regression, SVM and decision tree models typically perform well. Natural language however, does not fit well into the typical row and column structure (is instead called unstructured data), and contain a complexity much greater than ordinary tabular data.
To capture this great complexity in the data, we need a model that has great complexity as well. Therefore, deep learning has been a very important part of the development in NLP in recent years. Deep neural network models with an enormous amount of parameters, have the capacity to capture the complexity of natural language data. Besides recent large deep learning NLP models like BERT and XLNet, neural networks (although not deep ones) have also been used to produce word embeddings.
Word embeddings
We cannot use the raw text data just as it is for machine learning, since machine learning models only deal with numerical features. We therefore need some kind of numerical representation of the text data. Previous ways of doing this are one-hot encoding, bag-of-words or TF-IDF of all the words in the data. An alternative approach that is usually better, is to use word embeddings.
This means that we represent the words in the text as vectors in a large vector space. Word embedding models have been trained on very large word corpuses to create the vector space such that words that share common contexts in the training corpus will be close to each other in the vector space.
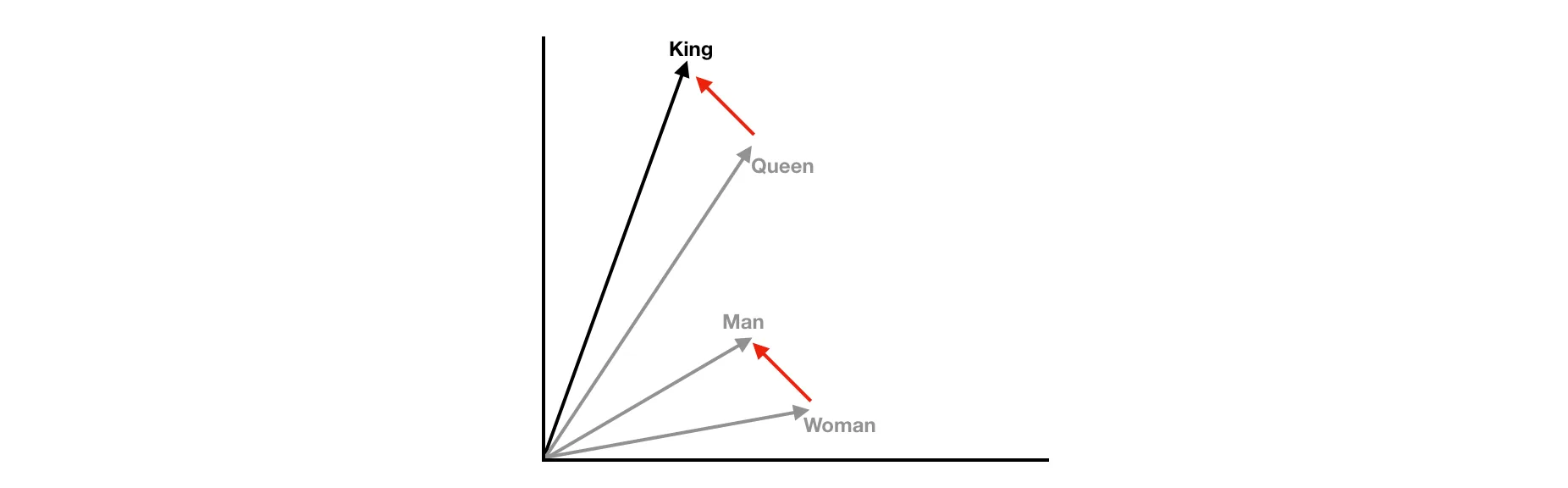 "Queen" + "Man" - "Woman" = "King"
"Queen" + "Man" - "Woman" = "King"The concept of representing words in a mathematical vector space may sound a bit abstract, but the idea is that words like "apple" and "pear" or "red" and "blue" will have similar word vectors. Another pretty cool thing is that we can perform arithmetic operations on these word vectors, such as:
"Queen" + "Man" - "Woman" = "King"
What can we do with text reviews?
After a short introduction to NLP, we will now connect back to the introduction. Using different NLP methods, one might now wonder what we can do with for example consumer text reviews about a company. This is what we will look into now.
We consider the following two consumer text review examples:
 Example consumer reviews.
Example consumer reviews.We will use these to illustrate the NLP tasks that we are going to look at.
The real use of NLP models however, is when they are applied to much data. We are therefore also going to look at some examples of what we can achieve when performing the tasks below on thousands of text reviews and aggregating the results.
Alright, it is time to look at some NLP tasks we can use to gain information from text reviews.
Sentiment text classification
We start with sentiment text classification, which is the task of classifying the sentiment of the whole text as either positive or negative. To accomplish this, we need our NLP text classifier model to detect the words that express sentiment in the text. Looking at the first review
 Example review text with positive words highlighted.
Example review text with positive words highlighted.we want our model to detect the words "great", "perfectly" and "pleased", all expressing positive sentiment, and thus classify this review as a positive one. Our second review expresses both positive and negative sentiments
 Example review text with both positive and negative words highlighted.
Example review text with both positive and negative words highlighted.and here it is not clear whether the review is positive or negative. One might argue that the text is positive because "really helpful" is stronger than "rather hard", something that a NLP text sentiment classifier may very well agree with. Another option is to extend the problem to not only have the two classes positive and negative, but include classes like neutral and/or conflict as well. This however result in a more complex multi-class classification problem.
Aggregated results
If we were to classify the sentiment of thousands of reviews for a company, we could get a sense of the overall opinion towards the company. Do people in general like or dislike this company, and does it perhaps change over time? Including the temporal aspect and classifying all of a company's reviews for each month, we could get this type of result:
 Positive and negative reviews for a company on a monthly basis.
Positive and negative reviews for a company on a monthly basis.Perhaps this is a software company that in the end of September released a new update of their program which was full of bugs, resulting in a lot of negative reviews in October and November before they managed to fix them and return to a majority of positive reviews again in December and forward. However, if the results for a company look like this instead:
 Positive and negative reviews for a company on a monthly basis.
Positive and negative reviews for a company on a monthly basis.where we have a clear trend of increasing negative sentiment from the consumers, this company has probably found an indication from their text classification analysis that they need to do something in order to improve the public opinion towards their company.
Aspect extraction
Next up we will take a look at aspect extraction. Aspect extraction means that we want to find the aspects that are being adressed in the text.
 Example review text with aspects highlighted.
Example review text with aspects highlighted.The first review example is about both the software and the service, while our second review addresses the website as well as the customer support.
 Example review text with aspects highlighted.
Example review text with aspects highlighted.Aggregated results
Let us consider a company selling consumer products, and that this company has a website where consumers can write reviews. These consumer reviews will then likely be used by other possible customers when they try to find out which products they want to buy.
Now if you for example want to buy a new phone, there might be some features of this phone that for you personally are more interesting than others. Perhaps the battery and the camera are very important to you, but you do not care too much about price or the size of the phone. You may therefore only be interested in reviews with mentions of the battery or the camera.
Having an NLP aspect extraction model, we can apply this to consumer reviews. If we stay with the phone example, we could do aspect extraction on all reviews regarding e.g. an iPhone 11. We can then tag all reviews with the aspects that we extract from the text, and if we then also aggregate this over all reviews we can end up with a list of the most frequently mentioned aspects in the reviews. For an iPhone 11, we might get the following list:
"Camera", "Battery", "Screen", "iOS", "Size", "Charger", "Button", "Display"
Customers reading the reviews can then be given the option to select one of these aspects, and get to see only the reviews that has been tagged with the chosen aspect. A customer could choose to see only reviews about the battery:
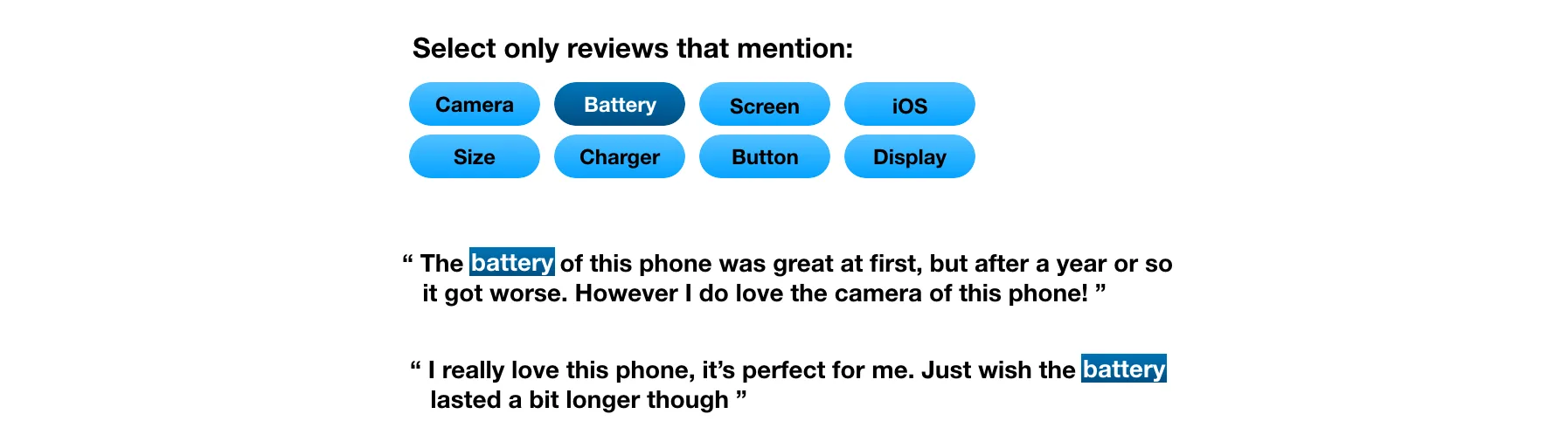 Read only the reviews mentioning the word "battery".
Read only the reviews mentioning the word "battery".or perhaps all reviews about the camera:
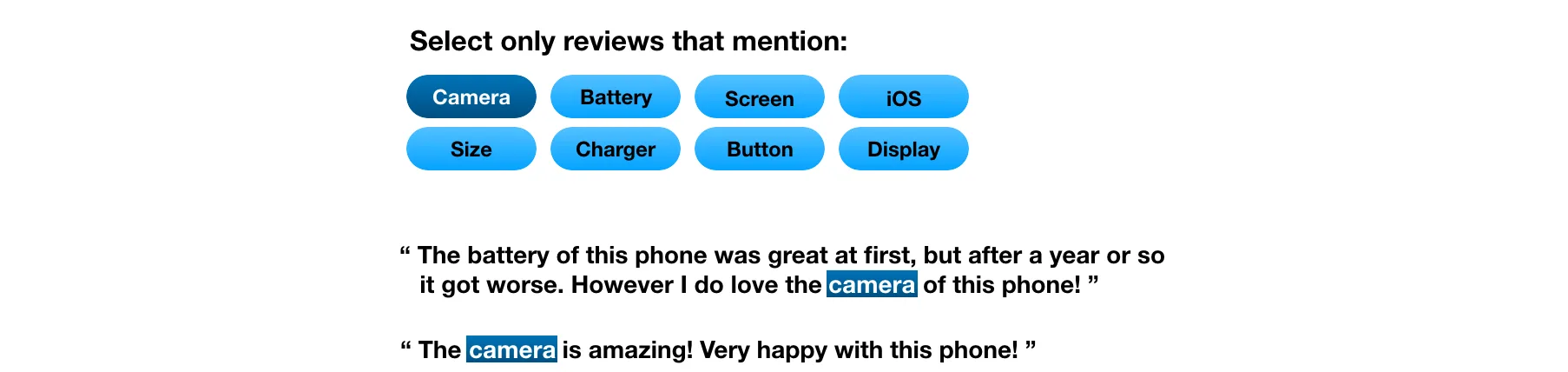 Read only the reviews mentioning the word "camera".
Read only the reviews mentioning the word "camera".This feature actually exist on Amazon's website today, but is interesting for practically all companies selling consumer products, and possibly also for other kind of companies with some modifications.
Aspect-based opinion mining
We move on to the next task, which is aspect-based opinion mining, also called aspect-based sentiment analysis. We can see this as a combination of our two previous tasks. We remember that our second example review expressed both positive and negative sentiment. More specifically, the author of the review disliked the website but was happy with the customer support.
 Example review text with opinion words linked to aspects.
Example review text with opinion words linked to aspects.In aspect-based opinion mining we do not try to find the overall sentiment of the entire text, but instead we try to find the sentiment towards every aspect mentioned in the text. We would like our opinion mining model to detect a negative sentiment for the website and a positive one towards the customer support.
Even if all sentiments expressed in the first review are positive, it is much more useful to know that these positive opinions regard the software and service, than just knowing that the review is positive.
 Example review text with opinion words linked to aspects.
Example review text with opinion words linked to aspects.Aggregated results
We will now look at what we could do with aspect-based opinion mining when we apply it to a lot of company reviews instead of just one. With sentiment text classification we saw that we could gain insights about the overall sentiment towards a company. With aspect-based opinion mining we are going to go a step further and find consumer sentiments for certain aspects of a company's business.
If we were to do this for e.g. a company selling phones, computers and other electronic products online, and displaying only the most mentioned aspect terms in their reviews, we might get the following results:
 Positive and negative opinions towards the most frequently mentioned aspects in the reviews of a company
Positive and negative opinions towards the most frequently mentioned aspects in the reviews of a companyThis of course provides much greater insights than just classifying the whole review as positive or negative. What consumers seem most concerned about is delivery, which in this case has mostly positive sentiment. Aspects that customers appear to be less satisfied with are price, computers and perhaps also the warranties. It might be time to reevaluate pricing and warranty policies, as well as reconsider the product sortiment for computers.
Depending on the type of aspect-based opinion mining model that is used, one could also be able to extract the opinion words related to the different aspects. Frequently stated opinions for "delivery" could perhaps be as follows:
Positive opinions | Number of Mentions | Negative opinions | Number of mentions |
|---|---|---|---|
Fast | 73 | Disappointing | 31 |
Good | 50 | Slow | 22 |
Quick | 46 | Bad | 18 |
These opinion words provide us with even more information and possibly actionable insights.
Named entity recognition
The last NLP task we will present, is named entity recognition. To best illustrate this task, we will leave our consumer review examples, and instead consider the following sentence:
 Example review text.
Example review text.In named entity recognition, we would like our NLP model to identify different types of entities in the text, for example names, locations, dates, organizations, time expressions, monetary values and percentages. So, in the text above we want to find the following entities with corresponding tags:
 Example review text annotated with entity type tags.
Example review text annotated with entity type tags.Aggregated results
Finally we will look at a use case of named entity recognition in connection to customer reviews, namely how it can be used to simplify the process of customer feedback handling.
Consider a company selling a wide range of products in multiple stores at different places. A lot of the customer reviews about this company might just be concerned with some specific store and possibly also a specific product. In order to deal with customer support and improve its business using customer feedback from reviews, it is of interest to distribute the reviews to the stores and product departments which the feedback regards, without someone first having to read the reviews.
To do this categorization of review texts automatically, named entity recognition can be used. Applying a named entity recognition model to the company's customer review texts, we can identify entities like countries, cities and product names in order to categorize thousands of reviews automatically, so that the different stores only receive feedback relevant for just them.
Let us look at a couple of example reviews. By finding the location entities in the following review using named entity recognition:
 Example review with entity tags.
Example review with entity tags.The review can automatically be categorized to regard the company's store in Paris, while the review below should be assigned to the London store, and possibly also be directed to the section of the store working with gaming consoles.
 Example review with entity tags.
Example review with entity tags.Having the ability to be automate this categorization of thousands of reviews greatly simplifies the customer feedback handling process.
Conclusion
Beside from introducing NLP and related concepts, we have in this blogpost looked at some of the things we can do with a text review using NLP models, in order to extract different kinds of information. Just looking at a single review however, give us only very little information and can be done quickly by ourselves. What is interesting is when we perform this type of tasks on thousands of text reviews and aggregate the results. That is when the NLP machine learning models become really useful and allow us to gain insights we had not been able to do efficiently on our own. That is why we also looked at some examples of what we can achieve by performing these tasks on thousands of reviews rather than just one.
These use cases that we introduced here are of course just some examples of what can be done with consumer reviews, and by using other types of textual data sources than reviews, we can do a lot of other things using NLP models. The possibilities are endless.
Published on March 3rd 2020
Last updated on March 1st 2023, 12:34

Fredrik Olsson
Data Scientist